
[PyTorch] 자주쓰는 Loss Function (Cross-Entropy, MSE) 정리
PyTorch에서 제가 개인적으로 자주쓰는 Loss Function (Cross Entropy, MSE) 들을 정리한 글입니다.
PyTorch nn 패키지에서는 딥러닝 학습에 필요한 여러가지 Loss 함수들을 제공합니다. 저는 Object Detection, Segmentation, Denoising 등의 이미지 처리에 주로 사용하는데, 항상 쓸 때마다 헷갈리고 document를 찾아보는걸 더 이상 하지 않고자 (특히 Cross Entropy 부분) 정리를 하게 되었습니다.
Cross-Entropy Loss 란?
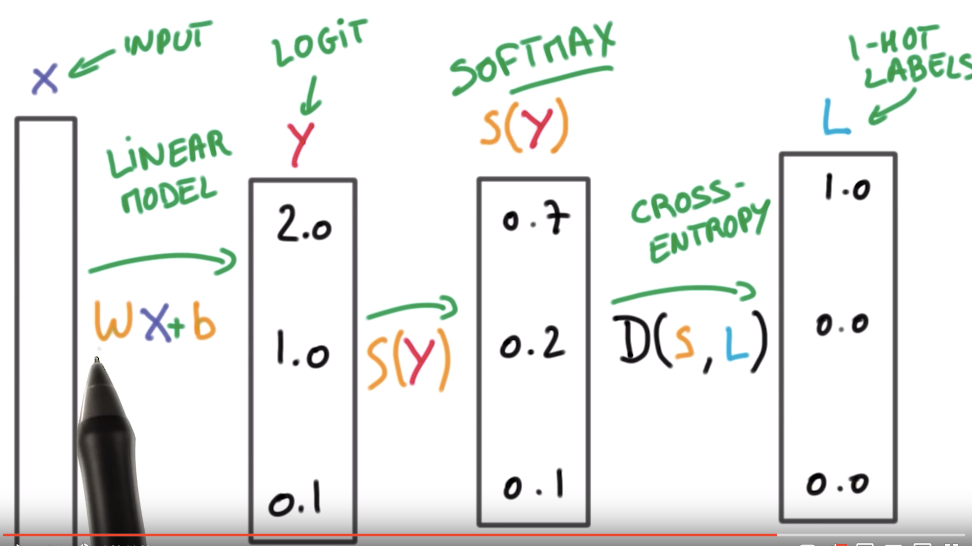
Cross Entropy Loss는 보통 Classification에서 많이 사용됩니다. 보통 위 그림과 같이 Linear Model (딥러닝 모델)을 통해서 최종값 (Logit 또는 스코어)이 나오고, Softmax 함수를 통해 이 값들의 범위는 [0,1], 총 합은 1이 되도록 합니다. 그 다음, 1-hot Label (정답 라벨)과의 Cross Entropy를 통해 Loss를 구하게 되죠.
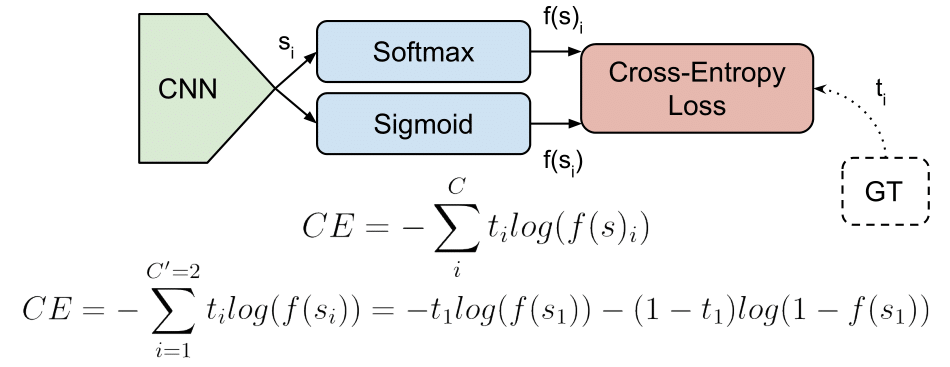
그리고 식은 위 그림과 같습니다. 정답 클래스에 해당하는 스코어에 대해서만 로그합을 구하여 최종 Loss를 구하게 됩니다.
Mean Squared Error 란?
Mean Squared Error (줄여서 MSE) 는 딥러닝에서 제가 가장 많이 사용했었던 loss 입니다. classification에서도 Cross-Entropy 대신 사용하기도 하고, denoising과 같은 image restoration task 에서는 image 간의 차이나 segmentation 에서는 mask 간의 차이를 구하기 위해 많이 사용합니다.
저희가 두 점 사이의 거리를 구하기 위해 사용했던 식을 생각하면 될 것 같습니다. 식은 다음과 같습니다. 여기서 output은 예측값, target은 정답값입니다.
\[{1 \over n}\sum_{i=1}^n(output_i-target_i)^2\]PyTorch Functions
CrossEntropyLoss
앞에서 배운바와 같이 Cross-Entropy Loss를 적용하기 위해서는 Softmax를 우선 해줘야 하나 생각할 수 있는데, PyTorch에서는 softmax와 cross-entropy를 합쳐놓은 것 을 제공하기 때문에 맨 마지막 layer가 softmax일 필요가 없습니다.
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
CrossEntropyLoss 함수는 다음과 같고, 이때 input tensor size는 일반적으로 (minibatch, Class) 입니다. 여기서 class의 range는 [0, C-1] 입니다. target의 shape은 (minibatch, ) 입니다. 이때 target[i]의 range는 [0, C-1] 입니다.

이를, 간단하게 그림으로 나타낸 것입니다.
실제 코드에서는 아래와 같이 작성을 합니다.
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
...
loss = criterion(input, target)
BCELoss
만약 class 가 2개인 binary case인 경우에는 BCELoss를 사용하시는 것이 좋습니다.
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
하지만, BCELoss에서는 CrossEntropyLoss와 같이 softmax를 포함한 것이 아닌, Cross Entropy만 구합니다. 따라서, 이 loss를 사용하는 경우엔 softmax 또는 다른 activation function을 따로 적용해주어야 합니다.
이 경우에는 binary class이기 때문에 input과 target 모두 (minibatch, ) shape을 갖습니다. 각 minibatch 마다 input 값의 range는 [0,1]이 될 것이고, target 값은 0 또는 1이 될 것입니다.
실제 사용할 때에는 다음과 같이 작성합니다.
import torch.nn as nn
criterion = nn.BCELoss()
...
loss = criterion(nn.Sigmoid(input), target) # 또는 nn.Softmax(input)
BCEWithLogitsLoss
이 loss는 위에서 소개한 BCELoss 앞에 Sigmoid layer 를 더한 것입니다. (Sigmoid + BCELoss) 따라서 따로 sigmoid 나 softmax를 해줄 필요가 없습니다.
torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None)
만약 Sigmoid를 사용한다면, Sigmoide 와 BCELoss를 사용하는 것 보다는 BCEWithLogitsLoss를 사용하는 것이 더 안정적이라고 합니다.
MSELoss
이 loss는 앞에서 설명드린 mean squared error 를 구하는 loss function 입니다.
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
여기서 input과 target의 shape은 (minibatch, …)으로 똑같아야 합니다. 예를 들어, 이미지 간의 mse loss를 구한다면, (minibatch, h, w, channel) 이 됩니다.

위 그림에서 각각을 2x2 mask라고 생각하면 쉽게 이해할 수 있을 것 같습니다.
코드에서 사용은 다음과 같습니다.
import torch.nn as nn
criterion = nn.MSELoss()
...
loss = criterion(input, target)
Reference:
[1] PyTorch Documentation
[2] Cross Entropy Loss - Raúl Gómez blog
[3] Understand Cross Entropy Loss in Minutes - Data Science Bootcamp
[4] BCELoss vs BCEWithLogitsLoss - PyTorch Forums
Leave a comment